
Online-Meetings sind mehr als gesprochene Worte
Die Covid19-Krise zeigt es klar: Online-Meetings beschränken sich nicht auf gesprochene Worte. Egal ob Yoga-Stunden, Gitarrenunterricht oder Gesangstraining, MS Teams & Co werden speziell im privaten Umfeld für die unterschiedlichsten Anwendungen verwendet. Viele Nutzer sind aber oft erstaunt, wie schlecht z.B. Musiksignale im Vergleich zur Sprache übertragen werden. Auch andere Alltagsgeräusche wie Vogelgezwitscher klingen sehr unnatürlich. Die Ursachen dafür sind im Bereich Rauschunterdrückung und Music Mode in Conferencing Tools zu finden.
Hier handelt es sich um ein riesiges „dirty litte audio secret“ der Plattform-Anbieter, über das es in diesem Artikel gehen soll. AEC (Acoustic Echo Cancelling) hat damit ausnahmsweise gar nichts zu tun.
Projektziel maximale Verständlichkeit
Es wäre logisch zu vermuten, dass unsere Conferencing-Tools das Audiosignal möglichst unverfälscht von A nach B zu übertragen versuchen. Man könnte auch glauben, dass eine möglichst natürliche Übertragung auch die beste Übertragung wäre. Doch NEIN, dies ist absolut nicht der Fall.
Ziel der Anbieter ist es vielmehr, bei der Gegenseite maximale Sprachverständlichkeit zu erzielen. Man will folglich eine „bessere“ Sprache übertragen, „einfacher zu hörende“ Signale.
In anderen Worten:
Alles an Audio-Trickserei ist erlaubt und wird somit auch verwendet, um maximale Sprachverständlichkeit zu erreichen. Das Original-Signal bleibt dabei auf der Strecke, solange nur der Mensch das Gefühl hat, sein Gegenüber optimal zu verstehen.
Audio-Werkzeuge zur Verbesserung der Sprachverständlichkeit
Sofort fallen uns einige altbewährte Maßnahmen ein, mit welchen die Sprachverständlichkeit verbessert werden kann:
- Einschränkung des Frequenzbereichs:
Frequenzen, welche von der menschlichen Stimme nicht verwendet werden, kann man bedenkenlos wegfiltern. Der Empfänger muss diese also nicht mehr herausfiltern, weil sie gar nicht erst übertragen werden. - Equalisation = Anhebung/Absenkung einzelner Frequenzbereiche
Durch gezielte Veränderung einzelner Frequenzbereiche erhöht man ebenfalls die Sprachverständlichkeit. Das Ergebnis klingt danach nicht immer schön oder „richtig“, aber verständlich ist es, weil eben mehr von den relevanten Signalanteilen übertragen werden. - AGC = Automatic Gain Control und Compression:
AGC bringt unterschiedlich starke Pegel auf einen gleichen Level. Laute Signale werden gedämpft, leise werden angehoben und dazwischen werden die Lautstärke-Unterschiede verkleinert. So lange, bis alles irgendwie gleich laut ist. Auch das soll den Hörkomfort beim Empfänger verbessern.
So weit so gut, diese Werkzeuge gibt es schon seit analogen Zeiten aber heutzutage ist ungleich mehr möglich! Alle bekannten Anbieter verwenden daher zusätzlich noch sehr spezielle Algorithmen, welche ganz tief in die Trickkiste der Psychoakustik greifen. Technisch gesehen hat das übertragene Signal immer weniger mit der menschlichen Stimme gemeinsam, aber für uns Menschen „funktioniert“ es! Unser Gehirn wird ausgetrickst.
Da geht noch viel mehr
Jede Menge Rechenpower in der Cloud, Neuronale Netzwerke und andere Technologien arbeiten dafür hinter den Kulissen. Cisco analysierte zum Training ihrer Systeme bisher z.B. 16 Mrd (!) Minuten Audio, welche über die Webex Plattform liefen! Das entspricht 29000 Jahre Non-Stop Gesprächen!
(Quelle: https://blog.webex.com/de/videokonferenzen/16-milliarden-minuten-storende-gerausche-verschwunden/ )
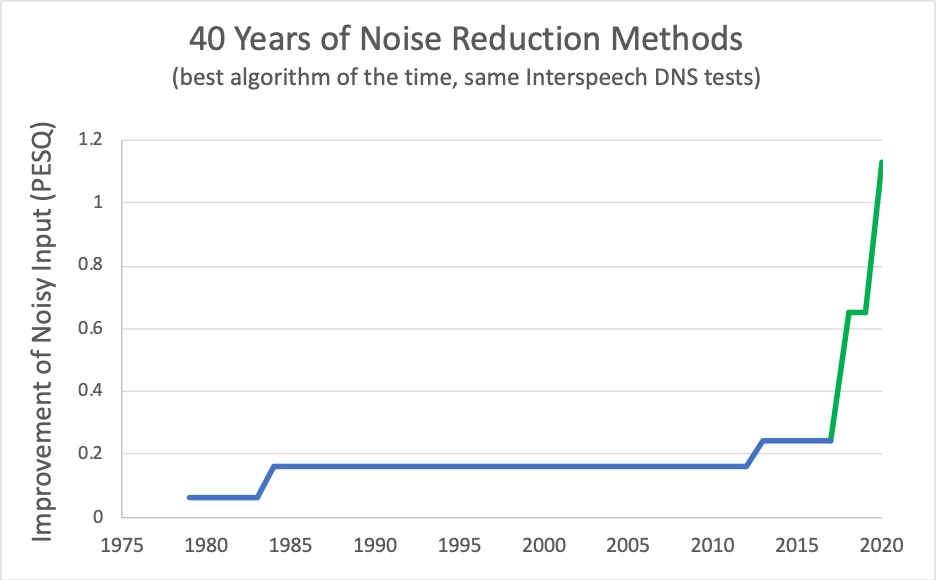
Dieses hochkomplexe Audioprocessing ist in der Lage, aus einem Gemisch an Signalen genau jene Anteile herauszufiltern bzw. zu verstärken, welche die größte Relevanz für das Verstehen der menschlichen Stimme haben. Sogar fehlende Teile können rekonstruiert.
Motto: Wenn die Bestandteile A, B und C da sind, D aber fehlt, so errechnet die Cloud eben den fehlenden Teil und fügt diesen hinzu! Am Ende erhält man ein Signal, welches ein Mensch als menschliche Stimme identifiziert bzw. im direkten Vergleich sogar als „richtiger“ oder einfacher verständlich bezeichnet! Die Kompromisse bzw. die Verluste durch die Aufnahme, die Raumakustik und die Übertragung werden mehr als nur kompensiert.
Die neuesten Algorithmen im Bereich Rauschunterdrückung und Music Mode unterscheiden sogar den Sprecher, der näher zum Mikrofon ist, von einer unbeteiligten anderen Person im Raum. Wohlgemerkt ganz ohne beam-tracking Mikrofone oder Bildanalyse, also ohne jegliche Lokalisierung, sondern einzig aus dem Audiosignal heraus! Das System findet also den „richtigen“ Sprecher im Raum und blendet die anderen Stimmen aus.
Erstaunlich, aber hören Sie selbst zwei Beispiele der Funktion „My Voice Only“ von Cisco Webex sowie der Geräuschunterdrückung von MS Teams.
Aber nicht alles ist ein Geräusch
Die Anbieter summieren alle diese Optimierungen unter dem Begriff Noise Reduction, Noise Suppression bzw. Rauschunterdrückung, obwohl es um viel mehr als nur um Rauschen geht.
Der aktuelle MS Teams Windows Client ist dazu sogar verblüffend ehrlich.
Im Hilfetext zur Option Rauschunterdrückung steht doch tatsächlich: „Unterdrücken von Hintergrundgeräuschen, welche keine Sprache sind“
Genauso so ist es: Alles, was keine Sprache ist, darf/soll/muss weg!
Was machen wir jetzt mit Musik?
Alle Signale, welche kein gesprochenes Wort sind, werden nun überhaupt nicht oder bestenfalls „verstümmelt“ übertragen. Das sind keine guten Nachrichten für den Online Cello-Unterricht oder die Zumba-Stunde via Zoom!
Aber selbst ohne diese „Rauschunterdrückung“ bleibt die Übertragungsqualität meist auf Sprach-Niveau. Musik, Gesang & Co benötigen jedoch einen deutlich besseren Transportweg.
Cisco Webex (hier) und Zoom (hier) bieten deshalb schon seit Monaten einen sogenannten Music-Mode an. Dieser soll genau diese Herausforderung lösen.
Dazu wird unter anderem die Datenrate für Audiosignale erhöht, also einfach „mehr“ Audio und in besserer Qualität (= größerer Frequenzbereich) übertragen. Auch wird weniger in die Dynamik eingegriffen, d.h. weniger bzw. gar kein AGC. Der Music Mode reduziert zusätzlich viele Audio-Tricksereien, welche uns Menschen das Verstehen des gesprochenen Worts erleichtern sollen, bei anderen Signalen aber stören oder deutlich hörbare Artefakte erzeugen.
Das Ergebnis kann durchaus überzeugen, hören Sie selbst:
Und was macht MS Teams? Die sind interessanterweise diesmal Nachzügler!
Obwohl Microsoft massiv versucht, Teams auch für Privatanwender interessant zu machen (https://www.microsoft.com/de-at/microsoft-teams/teams-for-home ), ist ein eigener Music-Mode für Teams erst in Entwicklung. Nach aktuellen Informationen sollte das Feature noch im Juli 2021 herauskommen, dieser Plan dürfte aber nicht halten. Warum bin ich mir so sicher? Nun ja, dieser Blogpost wird am letzten Arbeitstag des Juli 2021 veröffentlicht und noch ist weit und breit nichts davon zu sehen.
Update 18. Oktober 2021:
Der Music-Mode für MS Teams ist noch immer nicht aktiv. Trotz mehrfacher Ankündigung soll der Rollout nun endlich Ende November 20212 beginnen und im Jänner 2022 abgeschlossen sein.
Rauschunterdrückung und Music Mode in der Medientechnik
Obwohl diese Features primär für den Desktop und mobile Devices gedacht sind, können und sollten wir AV-Techniker dem Thema Rauschunterdrückung und Music Mode ebenfalls Bedeutung schenken. Deaktivieren bzw. Zurückfahren lohnt sich auf jeden Fall. Probeweise einfach einmal die entsprechenden Optionen ändern (z.B. auf Noise Reduction auf Stufe low statt high). Speziell die AGC-Funktion der Soft-Codecs greift ungleich brutaler zu als man es in einem hochwertigen fix installierten AV-System gerne hat.
Hier istoftmals weniger tatsächlich mehr in Sachen Hörkomfort und Natürlichkeit der Sprache.
Zusammenfassung und persönliche Meinung
Das Audioprocessing rund um Rauschunterdrückung und Music Mode bei den drei wichtigsten Collaborations-Plattformen hat ein enormes Ausmaß erreicht. Eine Vielzahl an High-Tech Tricks verändert das ursprüngliche Audiosignal oft bis zur (technischen!) Unkenntlichkeit, während es für den Menschen immer angenehmer klingen soll.
Ich habe so meine Zweifel, ob das wirklich der allerbeste Weg ist. Schießen wir hier vielleicht übers Ziel hinaus? Irgendwie erinnert mich das Thema ein wenig an phototrope (=selbsttönende) Brillengläser. Noch vor einigen Jahren also enormer Komfortgewinn gepriesen, sieht man dies mittlerweile anders. Grund dafür ist die Tatsache, dass unsere eigene Iris nicht mehr ausreichend als automatische Blende arbeiten muss, weil die Brille den Großteil des Ausgleichs unterschiedlicher Helligkeiten übernimmt.
Machen wir es hier unseren Ohren und unserem Gehirn zu einfach? Opfern wir hier die Natürlichkeit der Sprache für eine möglichst wenig anstrengende Hörbarkeit? Wie ist Ihre Meinung?
3 Kommentare zu „Rauschunterdrückung und Music Mode in Conferencing Tools“
Die Kommentare sind geschlossen.